279 SDN Data Centers and Security
279.1 Learning Objectives
By the end of this chapter, you will be able to:
- Optimize Data Center Traffic: Apply SDN flow classification strategies for mice and elephant flows
- Implement Anomaly Detection: Design SDN-based security monitoring using flow statistics
- Avoid Common Pitfalls: Recognize and prevent SDN deployment mistakes
- Address SDN Challenges: Identify and mitigate scalability and security concerns in SDN-based IoT
SDN can protect the network like a super-smart security guard!
279.1.1 The Sensor Squad Adventure: The Security Detective
One day, something strange happened in the smart city network. A sensor started sending WAY more messages than normal - thousands per second instead of just a few!
“That’s suspicious!” said Connie the Controller. “Normal sensors don’t behave like that. This could be an attack!”
Because Connie could see ALL the traffic in the entire network, she noticed the problem immediately. In the old days, each switch only saw its own traffic, so no one would have noticed!
Connie quickly created a new flow rule: “Messages from that suspicious sensor go to the ‘investigation zone’ instead of the regular network.” This is called quarantine - like putting a sick person in a separate room so others don’t get sick.
The team investigated and found that the sensor had been hacked! But because Connie caught it fast and isolated it, no damage was done to the rest of the network.
“This is why SDN is great for security,” Connie explained. “I can see everything, detect problems fast, and respond instantly!”
279.1.2 Key Words for Kids
| Word | What It Means |
|---|---|
| Anomaly Detection | Finding things that are different or strange (like a sensor sending way too many messages) |
| Quarantine | Separating something suspicious so it can’t harm the rest of the network |
| Flow Monitoring | Watching all the messages in the network to spot problems |
279.2 SDN for Data Centers
Data centers handle diverse traffic patterns that SDN can optimize:
Mice Flows: - Short-lived (< 10s) - Small size (< 1 MB) - Latency-sensitive - SDN Strategy: Wildcard rules for fast processing
Elephant Flows: - Long-lived (minutes to hours) - Large size (> 100 MB) - Throughput-sensitive - SDN Strategy: Exact-match rules with dedicated paths
Flow Classification: - Monitor initial packets to classify flow type - Install appropriate rules dynamically - Load balancing: distribute elephants across paths
279.3 Anomaly Detection with SDN
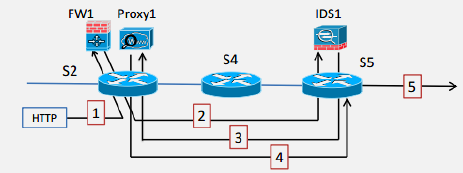
SDN enables real-time security monitoring through centralized visibility:
Detection Methods:
1. Flow Monitoring: - Track flow statistics (packet rate, byte rate) - Detect sudden spikes (DDoS, port scans) - Trigger alerts to controller
2. Port Statistics: - Monitor switch port utilization - Detect abnormal traffic patterns - Identify compromised devices
3. Pattern Matching: - Match against known attack signatures - Correlate flows across switches - Centralized view enables network-wide detection
Response: - Install blocking rules at source - Redirect traffic through IDS/IPS - Rate-limit suspicious flows - Isolate compromised devices
279.4 Common Pitfalls
The mistake: Deploying a single SDN controller for production IoT networks, creating a critical single point of failure. When the controller fails, new flows cannot be established and network management is lost.
Symptoms:
- New devices cannot connect during controller outage
- Network topology changes cause packet drops until controller recovers
- Controller restarts cause minutes of network disruption
- Network policies cannot be updated during outages
- Operations team has no failover procedure
Why it happens: SDN pilots start with a single controller for simplicity. The architecture works in development and testing. Teams plan to “add redundancy later” but the production launch deadline arrives first. Since existing flows continue working during brief outages, the problem seems manageable until a prolonged failure occurs.
The fix: Deploy redundant controllers from the start:
# SDN controller cluster configuration (OpenDaylight/ONOS pattern)
controller_config = {
"cluster": {
"name": "iot-sdn-cluster",
"nodes": [
{"id": "ctrl-1", "ip": "10.0.1.10", "role": "leader"},
{"id": "ctrl-2", "ip": "10.0.1.11", "role": "follower"},
{"id": "ctrl-3", "ip": "10.0.1.12", "role": "follower"}
],
"consensus": "raft", # Or Paxos
"leader_election_timeout_ms": 5000,
"heartbeat_interval_ms": 1000
},
"switch_config": {
# Switches connect to multiple controllers
"controller_list": [
"10.0.1.10:6653", # Primary
"10.0.1.11:6653", # Backup 1
"10.0.1.12:6653" # Backup 2
],
"controller_role": "equal", # or "master-slave"
"failover_mode": "secure" # Maintain flows on failover
}
}
# Health monitoring
def monitor_controller_cluster():
for node in controller_config["cluster"]["nodes"]:
health = check_controller_health(node["ip"])
if not health["responsive"]:
alert_ops_team(f"Controller {node['id']} unresponsive")
if node["role"] == "leader":
trigger_leader_election()Prevention:
- Deploy minimum 3 controllers for production (tolerates 1 failure)
- Use consensus protocols (Raft, Paxos) for state synchronization
- Configure switches with multiple controller addresses
- Implement health monitoring and automatic failover
- Test failover scenarios regularly (chaos engineering)
- Use out-of-band management network for controller communication
- Document and practice manual failover procedures
The mistake: Designing SDN policies that create more flow rules than switches can store, causing packet drops, controller overload, and network performance degradation.
Symptoms:
- Switches rejecting new flow rules (OFPET_FLOW_MOD_FAILED)
- Increasing PACKET_IN messages as rules expire/overflow
- Controller CPU spiking to 100%
- Random packet drops for “some” devices
- Network works with 100 devices, fails with 1,000
Why it happens: Each unique traffic flow requires a flow table entry. With IoT, you might have thousands of devices each communicating with multiple destinations. Teams create per-device, per-destination rules without considering switch TCAM (Ternary Content-Addressable Memory) limits. Commodity switches hold 2,000-8,000 rules; enterprise switches hold 16,000-128,000.
The fix: Design for flow table efficiency:
# Bad: O(n*m) rules - one per source-destination pair
def bad_create_device_rules(devices: list, destinations: list):
rules = []
for device in devices:
for dest in destinations:
rules.append({
"match": {"src_ip": device.ip, "dst_ip": dest.ip},
"actions": "output:calculated_port"
})
return rules # 1000 devices * 10 destinations = 10,000 rules!
# Good: O(n) rules - aggregate with wildcards
def good_create_device_rules(device_subnet: str, dest_subnets: list):
rules = []
# Single rule for entire device subnet
for dest in dest_subnets:
rules.append({
"match": {
"src_ip": device_subnet, # "10.0.0.0/16" covers all devices
"dst_ip": dest
},
"actions": "output:calculated_port",
"priority": 100
})
# Specific rules only for exceptions
rules.append({
"match": {"src_ip": "10.0.1.99"}, # Special device
"actions": "output:special_port",
"priority": 200 # Higher priority overrides
})
return rules # 10 subnet rules + exceptions
# Flow table monitoring
def monitor_flow_tables(switches: list):
for switch in switches:
stats = get_flow_table_stats(switch)
utilization = stats["active_entries"] / stats["max_entries"]
if utilization > 0.8:
alert_ops_team(
f"Switch {switch.id} flow table at {utilization:.0%} capacity"
)
# Consider: aggregate rules, increase timeouts, offload to controllerPrevention:
- Know your switch flow table limits (check datasheets)
- Use wildcard matching (subnet-based rules vs. per-IP rules)
- Implement proactive rule aggregation
- Set appropriate idle/hard timeouts to remove stale rules
- Monitor flow table utilization with alerts at 70% and 90%
- Use multi-table pipelines to organize rules efficiently
- Consider reactive-only for infrequent flows (accept PACKET_IN overhead)
- Evaluate switches with larger TCAM for IoT deployments
279.5 Worked Example: Microservices vs Monolith for IoT Backend
Scenario: A smart city platform needs to handle data from 100,000 sensors deployed across the city - traffic cameras, air quality monitors, parking sensors, street lights, and water meters. The platform must ingest sensor data, run analytics, and provide real-time dashboards for city operations.
Goal: Choose between a microservices architecture and a monolithic architecture for the IoT backend platform, considering scalability, team structure, and operational complexity.
What we do: Document the non-functional requirements that influence architecture choice.
Scale requirements: - 100,000 sensors with varying data rates - Peak ingestion: 500,000 messages/minute (traffic peaks during rush hour) - Average ingestion: 100,000 messages/minute - Data storage: 2 TB/month growing to 50 TB over 3 years - Analytics latency: Real-time alerts (<5 seconds), batch analytics (hourly)
Team context: - Development team: 8 engineers (2 senior, 4 mid-level, 2 junior) - Operations team: 2 DevOps engineers - Current expertise: Python, PostgreSQL, Docker, limited Kubernetes experience - Timeline: MVP in 6 months, full platform in 12 months
Availability requirements: - Emergency services integration: 99.9% uptime - Public dashboards: 99.5% uptime - Batch analytics: 95% uptime acceptable
Why: Architecture decisions must be grounded in concrete requirements. The team size and expertise matter as much as technical requirements - a sophisticated architecture requires operational capability to maintain it.
What we do: Assess how a monolithic architecture would address these requirements.
Proposed monolithic design:
+--------------------------------------------------------+
| Smart City Platform (Monolith) |
+--------------------------------------------------------+
| +--------------+ +--------------+ +--------------+ |
| | Ingestion | | Storage | | Analytics | |
| | Module | | Module | | Module | |
| +--------------+ +--------------+ +--------------+ |
| +--------------+ +--------------+ +--------------+ |
| | Alerting | | API | | Dashboard | |
| | Module | | Module | | Module | |
| +--------------+ +--------------+ +--------------+ |
+--------------------------------------------------------+
| Shared Database (PostgreSQL with TimescaleDB) |
+--------------------------------------------------------+Monolith advantages for this scenario: - Simpler development: Single codebase, shared data models, easier debugging - Lower operational complexity: One deployment unit, one log stream, simpler monitoring - Team capability match: 8-person team can fully understand the system - Faster MVP: Less infrastructure setup, focus on features - Cost-effective: Fewer cloud resources, no service mesh overhead
Monolith challenges: - Scaling limitation: Must scale entire application even if only ingestion needs more capacity - Deployment coupling: Analytics bug requires redeploying ingestion (risk) - Team blocking: Merge conflicts if multiple features developed simultaneously - Technology lock-in: Entire application uses same language/framework
Scalability assessment: - Horizontal scaling possible with load balancer and read replicas - 500K messages/minute achievable with 4-8 application instances - TimescaleDB handles time-series data efficiently - Estimated infrastructure: 8 x c5.2xlarge ($2,400/month)
What we do: Assess how a microservices architecture would address these requirements.
Microservices advantages: - Independent scaling: Scale ingestion to 20 instances during rush hour, keep analytics at 4 - Technology flexibility: Use Go for high-throughput ingestion, Python for ML analytics - Independent deployment: Update alerting without touching ingestion - Fault isolation: Storage service crash doesn’t immediately affect ingestion (buffered in Kafka) - Team independence: Separate teams can own separate services
Microservices challenges for this scenario: - Operational complexity: Kubernetes, Istio, distributed tracing, multi-database management - Team expertise gap: Limited Kubernetes experience, only 2 DevOps engineers - Distributed system challenges: Network latency, eventual consistency, distributed transactions - Higher infrastructure cost: Service mesh, multiple databases, Kafka cluster - Slower initial velocity: Infrastructure setup takes 2-3 months before feature work
Scalability assessment: - Elastic scaling from 10 to 100 instances per service - Kafka handles 500K messages/minute easily (single partition does 100K/minute) - ClickHouse optimal for analytics queries on large datasets - Estimated infrastructure: ~$8,000/month (Kubernetes + managed databases + Kafka)
What we do: Create a decision matrix comparing both approaches against requirements.
Decision matrix:
| Factor | Monolith | Microservices | Weight | Winner |
|---|---|---|---|---|
| Scalability | Good (8 instances) | Excellent (per-service) | 25% | Microservices |
| Development velocity | Fast (single codebase) | Slower (coordination) | 20% | Monolith |
| Operational complexity | Low (team can manage) | High (expertise gap) | 20% | Monolith |
| Fault isolation | Poor (coupled) | Excellent | 15% | Microservices |
| Time to MVP | 4 months | 6+ months | 10% | Monolith |
| Cost (year 1) | $30K | $100K | 10% | Monolith |
| Long-term scalability | Limited (refactor later) | Future-proof | - | Microservices |
Critical insight: The 8-person team with limited Kubernetes experience is the deciding factor. Microservices require significant operational maturity. Choosing microservices prematurely leads to slower feature delivery, operational incidents, team burnout, and budget overruns.
What we do: Design a pragmatic “modular monolith” that can evolve to microservices.
Key design principles:
- Module boundaries: Each module has clean interfaces (internal APIs)
- Ingestion doesn’t directly access Analytics database tables
- Communication through defined contracts (like future service APIs)
- Enables future extraction without rewriting logic
- Kafka for decoupling: Even in monolith, use Kafka for ingestion
- Ingestion module publishes to Kafka topics
- Analytics module consumes from topics
- When extracting to microservices, Kafka contract remains unchanged
- Database schemas as boundaries:
- Each module owns its schema (e.g.,
ingestion.*,analytics.*) - No cross-schema foreign keys (referential integrity via application)
- Enables future database split
- Each module owns its schema (e.g.,
- Preparation for extraction:
- When ingestion needs independent scaling, extract to separate service
- Kafka already in place, schema already isolated
- Extraction takes weeks, not months
Why: This approach delivers MVP on time with a small team while building toward future scalability.
Architecture chosen: Modular Monolith with planned evolution path
Key decisions made:
| Decision | Choice | Rationale |
|---|---|---|
| Initial architecture | Modular monolith | Matches team size and expertise |
| Inter-module communication | Internal APIs + Kafka | Prepares for future extraction |
| Database strategy | Single database, isolated schemas | Simpler ops now, splittable later |
| First extraction target | Ingestion service | Highest scale requirements |
| Extraction trigger | P99 latency > 500ms | Objective, measurable threshold |
| Technology stack | Python + PostgreSQL + Kafka | Team expertise, proven at scale |
Outcome achieved: - MVP delivered in 4 months (on schedule) - Team maintains system confidently with existing skills - Platform handles 100,000 sensors with 4 instances - Clear, documented path to microservices when scale demands - Infrastructure cost: $35K/year (vs. $100K for premature microservices) - Team velocity: 2x faster than microservices approach
Key insight: “Microservices are not a goal; they’re a tool for specific scaling and organizational challenges. Start with the simplest architecture that meets current requirements, and evolve when concrete triggers fire.”
279.6 Chapter Summary
This chapter covered SDN applications in data centers and security:
Data Center SDN: Flow classification distinguishes mice flows (small, latency-sensitive) from elephant flows (large, throughput-sensitive). SDN controllers route elephant flows through underutilized links while keeping mice on shortest paths, improving overall network utilization by 30-50%.
Anomaly Detection: SDN’s centralized visibility enables real-time security monitoring. Controllers can detect traffic anomalies (DDoS, port scans, compromised devices) through flow statistics and respond automatically with rate limiting, quarantine, or traffic redirection.
Common Pitfalls: Single controller deployments create dangerous single points of failure - always deploy redundant controllers. Flow table overflow from excessive per-device rules requires wildcard aggregation and monitoring.
Architecture Decision: Choose architecture based on team capability and concrete requirements, not industry trends. Modular monoliths with clear boundaries can evolve to microservices when scale demands it.
279.7 Visual Reference Gallery


279.8 Further Reading
Kreutz, D., et al. (2015). “Software-defined networking: A comprehensive survey.” Proceedings of the IEEE, 103(1), 14-76.
McKeown, N., et al. (2008). “OpenFlow: enabling innovation in campus networks.” ACM SIGCOMM Computer Communication Review, 38(2), 69-74.
Hakiri, A., et al. (2014). “Leveraging SDN for the 5G networks: Trends, prospects and challenges.” arXiv preprint arXiv:1506.02876.
Galluccio, L., et al. (2015). “SDN-WISE: Design, prototyping and experimentation of a stateful SDN solution for WIreless SEnsor networks.” IEEE INFOCOM, 513-521.
279.10 What’s Next?
Building on these architectural concepts, the next section examines Sensor Node Behaviors.