Understand Fog Architecture: Explain the edge-fog-cloud continuum and hierarchical processing
Apply Academic Frameworks: Use research-based models for fog computing design
Recognize Paradigm Shift: Understand how fog changes traditional cloud-centric thinking
Evaluate Time Sensitivity: Map application latency requirements to appropriate tiers
340.2 Introduction to Fog Computing
⏱️ ~10 min | ⭐⭐ Intermediate | 📋 P05.C07.U01
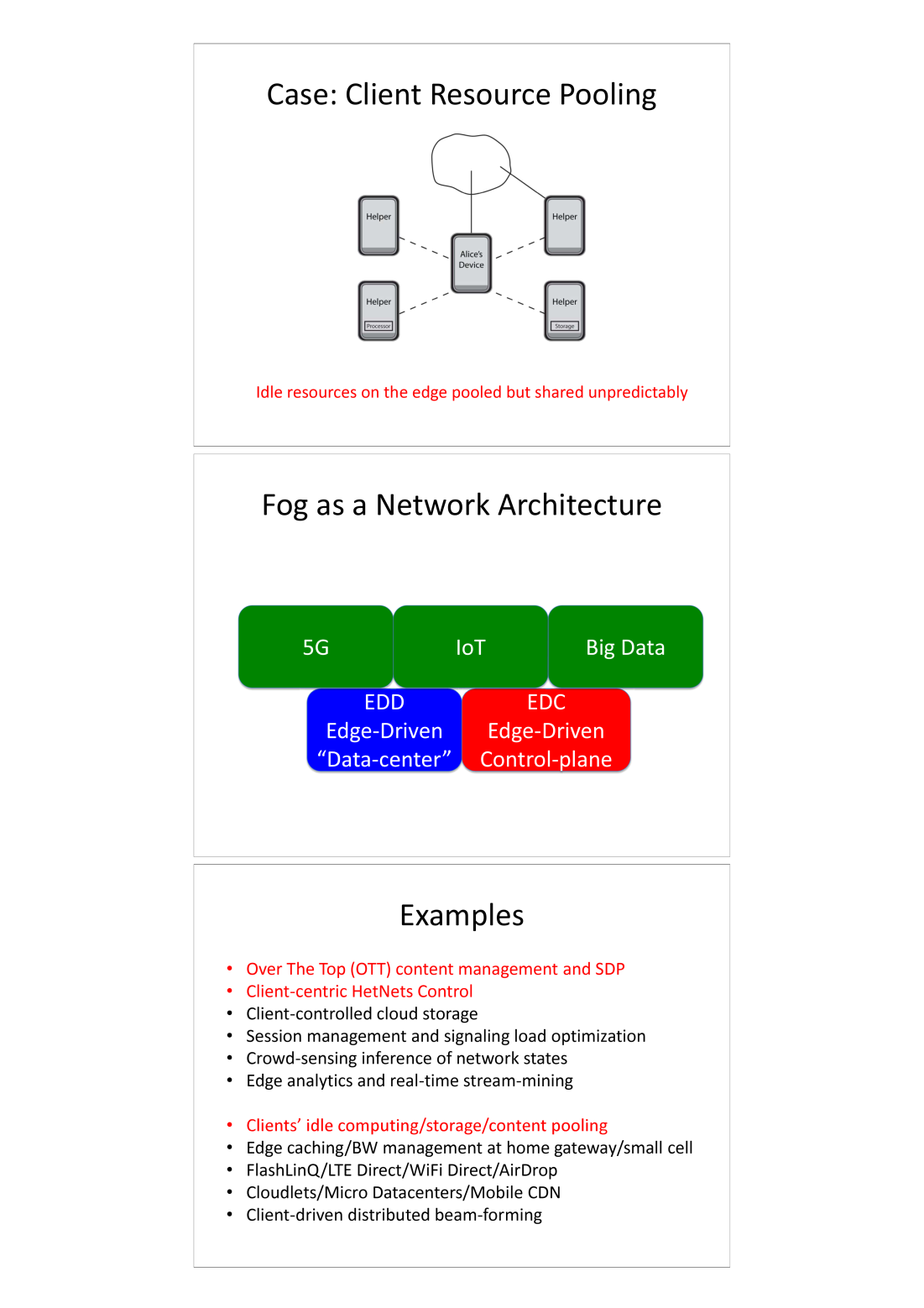
NoteAcademic Resource: Fog as a Network Architecture
Fog computing architecture diagram showing how 5G, IoT, and Big Data converge at the edge, with Edge-Driven Data-center (EDD) and Edge-Driven Control-plane (EDC) concepts. The diagram illustrates client resource pooling where idle resources on edge devices are shared unpredictably, creating distributed processing capabilities closer to data sources.
Source: Princeton University, Coursera Fog Networks for IoT (Prof. Mung Chiang)
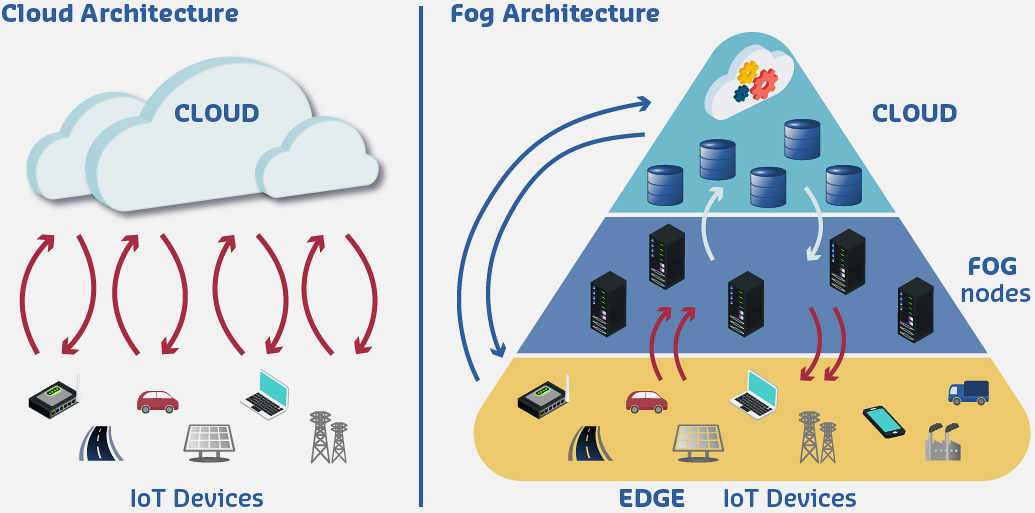
Fog computing, also known as edge computing or fogging, extends cloud computing capabilities to the edge of the network, bringing computation, storage, and networking services closer to data sources and end users. This paradigm emerged to address the limitations of purely cloud-centric architectures in latency-sensitive, bandwidth-constrained, and geographically distributed IoT deployments.
Graph diagram
Figure 340.1: Edge-Fog-Cloud computing continuum showing the three-tier architecture with computational capabilities, latency characteristics, and data flow patterns between layers. Edge provides millisecond responses for critical applications, fog enables local analytics with 90-99% bandwidth reduction, and cloud delivers unlimited compute for global intelligence.
Graph diagram
Figure 340.2: Data time sensitivity classification mapping latency requirements to appropriate computing tiers. Critical applications (<10ms) demand edge processing for safety, real-time applications (10-100ms) benefit from fog layer analytics, interactive applications (100ms-1s) can use fog or cloud, and batch analytics (>1s) leverage cloud computational power.
Graph diagram
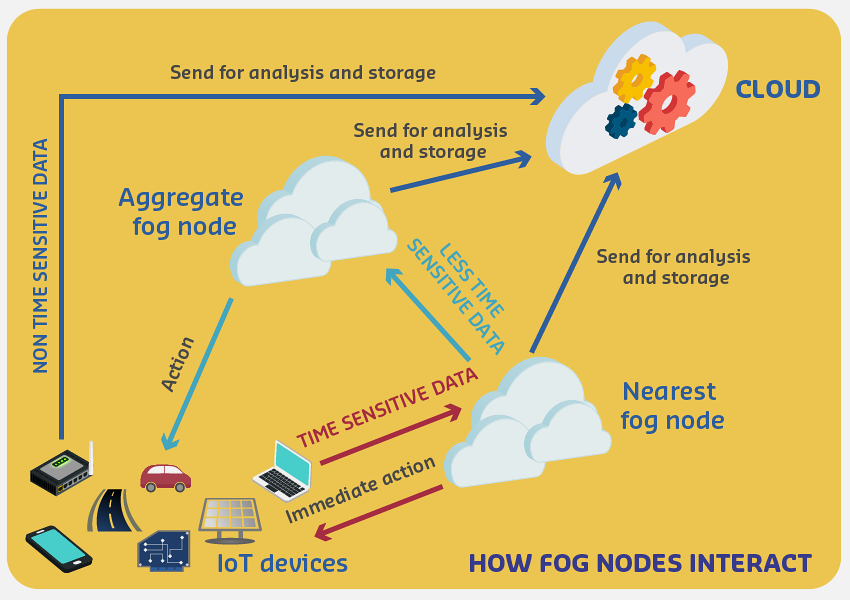
Figure 340.3: Smart home fog computing architecture demonstrating local intelligence at the fog gateway processing data from diverse sensors (temperature, motion, door locks, power) using multiple protocols (Zigbee, Z-Wave, Wi-Fi). The fog layer performs sub-10ms local automation, aggregates data before cloud transmission, and maintains autonomous operation during internet outages while the cloud provides ML model updates and long-term analytics.
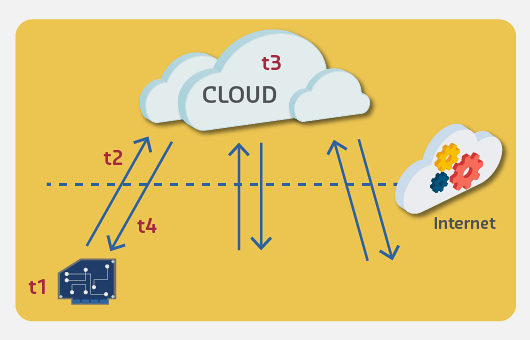
Figure 340.6: Fog and edge computing time considerations
Figure 340.7: Characteristics of fog computing
TipDefinition
Fog Computing is a distributed computing paradigm that extends cloud computing to the edge of the network, providing compute, storage, and networking services between end devices and traditional cloud data centers. It enables data processing at or near the data source to reduce latency, conserve bandwidth, and improve responsiveness for time-critical applications.
WarningCommon Misconception: “Fog = Edge”
The Misconception: Fog computing and edge computing are the same thing.
Why It’s Wrong: - Edge: Processing ON the device or gateway (flat) - Fog: Hierarchical layers BETWEEN edge and cloud - Fog can have multiple tiers (edge → fog → cloud) - Fog implies orchestration and workload migration - Edge is simpler but less flexible
Real-World Example: - Smart city traffic system: - Edge: Traffic camera does object detection locally - Fog: City district server aggregates 100 cameras, runs city-wide optimization - Cloud: National traffic analysis, model training - The fog layer doesn’t exist in pure “edge” architecture
The Correct Understanding: | Aspect | Edge | Fog | Cloud | |——–|——|—–|——-| | Location | Device/gateway | Between edge and cloud | Data center | | Latency | <10ms | 10-100ms | 100-500ms | | Compute | Limited | Moderate | Unlimited | | Scope | Single device | Regional | Global | | Management | Device-centric | Orchestrated | Centralized |
Fog is a hierarchy; edge is a location. They’re complementary, not synonymous.
340.2.1 Historical Context
Cloud Computing Dominance (2000s-2010s): Cloud computing revolutionized IT by providing scalable, on-demand resources through centralized data centers. However, as IoT proliferated, limitations became apparent for certain applications requiring low latency, high bandwidth, or local data processing.
Emergence of Fog Computing (2012-Present): Cisco introduced the term “fog computing” in 2012 to describe distributed computing infrastructure closer to IoT devices. The concept gained traction as IoT deployments grew and edge processing capabilities advanced.
Edge Computing Evolution: Edge computing encompasses similar concepts, with some defining it as processing at the very edge (on devices) while fog computing operates at the network edge (gateways, base stations). In practice, the terms are often used interchangeably.
340.2.2 Core Principles
Proximity to Data Sources: Fog nodes are positioned close to IoT devices, minimizing network hops and transmission distances.
Distributed Architecture: Processing and storage distributed across multiple fog nodes rather than concentrated in distant data centers.
Hierarchical Organization: Multi-tier architecture from edge devices through fog nodes to cloud, with processing at appropriate levels.
Low Latency: Local processing enables millisecond-level response times critical for real-time applications.
Bandwidth Optimization: Local processing and filtering reduce data transmitted to cloud, conserving bandwidth and reducing costs.
Context Awareness: Fog nodes leverage location, time, and environmental context for intelligent processing and decision-making.
Figure 340.8: Key characteristics of fog computing: low latency, location awareness, geographical distribution, large-scale sensor networks, mobility support, real-time interactions, and heterogeneity
340.3 The Fog Computing Paradigm Shift
⏱️ ~8 min | ⭐⭐ Intermediate | 📋 P05.C07.U02
Fog computing represents more than just a technical architecture—it fundamentally transforms how we think about infrastructure, computation, and network design. This section explores the provocative “what if” scenarios and memorable frameworks that illustrate fog computing’s revolutionary impact.
340.3.1 What If: Reimagining Network Infrastructure
WarningWhat If… The Edge Becomes the Infrastructure?
Consider these provocative scenarios that challenge traditional cloud-centric thinking:
What if the set-top box in your living room replaces the DPI box? - Deep Packet Inspection (DPI) typically happens at ISP facilities - Your set-top box has idle CPU 95% of the time (only peaks during video processing) - Fog vision: Distribute DPI across millions of home devices, creating a massive distributed firewall
What if the dashboard in your car is your cloud caching content? - Traditional: Stream Netflix from distant data center (uses cellular data) - Fog vision: Car dashboard caches popular content from nearby vehicles or roadside fog nodes (Wi-Fi/5G mesh) - Result: Zero cellular data cost, works in tunnels, instant playback
What if your phone (and other phones) become LTE PDN-GW & PCRF? - PDN Gateway (Packet Data Network Gateway) routes mobile data - PCRF (Policy and Charging Rules Function) manages network policies - Fog vision: Phones become micro-base-stations, routing traffic for nearby devices - Result: Resilient mesh networks that survive cellular tower failures
What if your router was a data center? - Modern routers: quad-core ARM, 1 GB RAM, 4 GB storage (idle 90% of time) - Fog vision: Run containerized services locally (DNS, DHCP, content filtering, VPN, local cloud storage) - Result: ISP outage? Your local network continues working with cached services
What if your smartwatch was a base station? - Smartwatches have Bluetooth, Wi-Fi, cellular connectivity - Fog vision: Smartwatches relay messages for nearby IoT devices, forming body-area network gateways - Result: Your fitness tracker talks to your smartwatch, which aggregates and sends to fog node—battery life 10× longer
Key Insight: Fog computing transforms clients from passive consumers into active infrastructure participants. Every device with compute capability becomes a potential fog node.
340.3.2 Paradigm Transformation: Clients USE vs Clients ARE
Traditional cloud computing views clients as consumers of infrastructure. Fog computing recognizes that clients themselves constitute infrastructure.
Graph diagram
Figure 340.9: Paradigm shift from cloud-centric to fog-distributed computing. Traditional cloud computing: clients USE centralized remote infrastructure as passive consumers. Fog computing: clients ARE (part of) the infrastructure, contributing processing, storage, and networking as active participants in a distributed system.
Traditional Cloud Model: - Clients are dumb terminals or thin clients - All intelligence resides in centralized data centers - Clients request, cloud provides - Infrastructure = distant servers and networks
Fog Computing Model: - Clients are computational resources - Intelligence distributed across edge, fog, and cloud - Clients contribute to and consume from infrastructure - Infrastructure = every device with compute capability
Real-World Example:
Scenario
Traditional Cloud
Fog Computing
Video Streaming
10,000 users stream from central CDN → 10,000 × 5 Mbps = 50 Gbps backbone load
Users cache and share with nearby devices → 90% served locally, 5 Gbps backbone load
Software Updates
1 million devices download 500 MB update = 500 TB from cloud
First 100 devices download from cloud, others peer-to-peer = 50 TB from cloud (10× reduction)
Sensor Aggregation
5,000 sensors × 100 bytes/sec = 500 KB/sec to cloud
Edge aggregates 100 sensors → 1 fog node, 50 fog nodes send 10 KB/sec each = 500 KB/sec total, 10 KB/sec per uplink
Cross-Reference: This paradigm shift enables the Edge AI/ML revolution, where client devices become ML inference engines rather than just data collectors. See also Edge-Fog-Cloud Overview for continuum architecture details.
Show code
viewof kc_fog_4 = {const container =html`<div class="inline-knowledge-check"></div>`;if (container &&typeof InlineKnowledgeCheck !=='undefined') { container.innerHTML=''; container.appendChild(InlineKnowledgeCheck.create({question:"A smart home has 50 IoT devices including smart lights, thermostats, and security cameras. The home router (quad-core ARM, 1GB RAM) sits idle 90% of the time. In the fog computing paradigm, what role could this router play?",options: [ {text:"None - routers are networking devices and shouldn't run compute workloads",correct:false,feedback:"Incorrect. This reflects the old cloud-centric view where clients only consume services. Modern fog computing recognizes that idle compute resources (like home routers) can contribute to local processing, running services like local DNS, smart home automation, and data aggregation."}, {text:"Backup cloud server - replicate cloud services locally for disaster recovery",correct:false,feedback:"Incorrect. While routers can provide some local functionality, they lack the resources to replicate full cloud services. The fog paradigm isn't about replicating cloud - it's about enabling local processing appropriate to the device's capabilities."}, {text:"Local fog node - run containerized services for home automation, DNS, content filtering, and data aggregation",correct:true,feedback:"Correct! The fog paradigm transforms clients from passive consumers ('USE infrastructure') to active participants ('ARE infrastructure'). A home router can run Docker containers for local automation logic, DNS caching, content filtering, and IoT data aggregation - all with sub-10ms latency and working during internet outages."}, {text:"Mining node - use the idle CPU cycles for cryptocurrency mining to offset costs",correct:false,feedback:"Incorrect. While technically possible, cryptocurrency mining isn't a fog computing use case. Fog computing focuses on processing IoT data locally for latency reduction, bandwidth savings, and offline operation - not general-purpose compute."} ],difficulty:"medium",topic:"fog-paradigm-shift" })); }return container;}
340.3.3 Click vs Brick: The Memorable Comparison
A memorable way to understand fog computing’s unique value is the “Click vs Brick” framework:
“Click” Characteristics (Cloud Computing): - Virtual: Everything accessed via browser/apps (one click away) - Scalable: Infinite resources on demand - Centralized: Single source of truth - Best for: Storage, big data analytics, ML model training
“Brick” Characteristics (Fog Computing): - Physical: Tied to specific locations and devices - Localized: Resources bounded by geography - Distributed: Many sources of local truth - Best for: Real-time control, low-latency responses, local autonomy
Example: Smart City Traffic Management
Cloud (Click) Approach:
10,000 traffic cameras → Cloud data center (1,000 km away)
↓
Process all video streams centrally (200ms latency)
↓
Send control commands back to traffic lights
↓
Total latency: 400ms (too slow for adaptive control)
Fog (Brick) Approach:
100 cameras → Local fog node at intersection
↓
Process video locally, detect congestion (5ms latency)
↓
Adjust traffic lights immediately
↓
Total latency: 10ms (enables real-time adaptation)
Why “Brick”? Physical infrastructure (like bricks in a building) stays local, provides structural support, and creates tangible presence. Fog nodes are the “bricks” that form the foundation of distributed IoT systems.
Show code
viewof kc_fog_5 = {const container =html`<div class="inline-knowledge-check"></div>`;if (container &&typeof InlineKnowledgeCheck !=='undefined') { container.innerHTML=''; container.appendChild(InlineKnowledgeCheck.create({question:"A retail chain wants to deploy AI-powered customer analytics in 500 stores. They need to count customers, analyze traffic patterns, and optimize store layouts. Using the 'Click vs Brick' framework, which approach makes more sense?",options: [ {text:"Click (Cloud) - centralized ML models can be updated instantly across all 500 stores",correct:false,feedback:"Incorrect. While cloud offers instant model updates ('Click'), video streaming from 500 stores would require massive bandwidth (500 stores × 10 cameras × 5 Mbps = 25 Gbps continuous upload). The 'Brick' approach with local inference is more practical."}, {text:"Brick (Fog) - process video locally at each store, send only analytics summaries to cloud",correct:true,feedback:"Correct! The 'Brick' approach deploys fog nodes at each store for local video processing. Customer counts and heatmaps are computed locally (real-time, privacy-preserving), while only aggregated insights are sent to cloud. This provides 99%+ bandwidth reduction and keeps personal data local for GDPR compliance."}, {text:"Click (Cloud) - cloud has unlimited GPU resources for advanced ML inference",correct:false,feedback:"Incorrect. While cloud does have more compute, the bottleneck is bandwidth, not processing power. Uploading raw video from 500 stores is prohibitively expensive ($500K+/month in bandwidth alone). Fog nodes with edge GPUs can run the same models locally at 1/100th the cost."}, {text:"Neither - this use case doesn't fit the Click vs Brick framework",correct:false,feedback:"Incorrect. This is actually a perfect example of the Click vs Brick tradeoff. 'Click' offers centralization and easy updates; 'Brick' offers local processing and bandwidth savings. For video analytics with privacy requirements, 'Brick' (fog) is clearly superior."} ],difficulty:"medium",topic:"fog-click-vs-brick" })); }return container;}
340.3.4 The Network Function Trinity
Fog computing intersects with three major networking paradigms: Relocate (Fog), Redefine (CCN), and Virtualize (NFV). Understanding their relationships reveals fog’s broader context.
Graph diagram
Figure 340.10: Network Function Trinity: Fog (Relocate), CCN (Redefine), NFV (Virtualize). Fog computing relocates processing to the edge for latency reduction. Content-Centric Networking (CCN) redefines networking around named data instead of locations for efficient caching. Network Function Virtualization (NFV) virtualizes network functions as software for flexible deployment. Overlapping areas represent hybrid approaches combining paradigms.
1. RELOCATE: Fog Computing - Core Concept: Move computation closer to data sources - Mechanism: Deploy processing at edge nodes instead of centralized clouds - Benefit: Latency reduction (400ms → 10ms), bandwidth savings (99% reduction) - Example: Industrial gateway processes sensor data locally, sends only anomalies to cloud
2. REDEFINE: Content-Centric Networking (CCN) - Core Concept: Name data, not locations (e.g., request “video123” instead of “server42.example.com/video123”) - Mechanism: Network caches content at intermediate routers, serves requests from nearest cache - Benefit: Efficient content delivery, reduced backbone traffic - Example: Request popular video → served from local cache instead of distant origin server
3. VIRTUALIZE: Network Function Virtualization (NFV) - Core Concept: Replace hardware appliances (firewalls, load balancers) with software functions - Mechanism: Run network functions as virtual machines or containers on commodity hardware - Benefit: Rapid deployment, dynamic scaling, cost reduction - Example: Spin up firewall container in 30 seconds versus 30-day hardware procurement
Intersections (Powerful Hybrid Approaches):
Combination
Name
Description
Example
Fog + CCN
Edge-Cached Content Delivery
Named data cached at fog nodes
Smart home caches firmware updates, serves to local devices
Fog + NFV
Virtualized Fog Services
Network functions deployed as containers at edge
Fog node runs firewall, VPN, and load balancer as Docker containers
CCN + NFV
Software-Defined CDN
Virtualized content delivery network
Cloud spins up CDN containers based on traffic patterns
5G MEC combines all three paradigms: - RELOCATE: Processing at cell tower edge (10ms from devices) - REDEFINE: Content named and cached at edge (popular videos, maps) - VIRTUALIZE: Services run as containers (gaming servers, AR processing)
Result: Ultra-low latency (1-10ms), massive bandwidth savings (90%+ reduction), instant service deployment (minutes instead of months).
Fog computing success requires expertise across multiple domains. No single discipline can deliver complete fog solutions—collaboration is essential.
Graph diagram
Figure 340.11: Fog computing interdisciplinary ecosystem showing five interconnected domains. Network Engineering provides protocols and connectivity, Device Hardware/OS enables edge execution, HCI & App UI/UX creates user experiences, Economics & Pricing validates business models, and Data Science extracts intelligence. Each domain depends on others in a continuous cycle.
2. Device Hardware & Operating Systems - Responsibilities: Select fog hardware (ARM, x86, FPGA), manage containerized workloads - Challenges: Resource constraints (CPU, memory, power), thermal management, longevity - Example: Run Docker containers on Raspberry Pi 4 with automatic failover
3. Human-Computer Interaction (HCI) & App UI/UX - Responsibilities: Design local-first applications, graceful degradation during outages - Challenges: Sync conflicts, offline UX, latency feedback to users - Example: Mobile app works offline, syncs when fog node reachable, shows sync status
4. Economics & Pricing - Responsibilities: Calculate TCO (Total Cost of Ownership), compare edge vs cloud costs - Challenges: Hidden costs (maintenance, updates, energy), ROI uncertainty - Example: Fog node costs $2,000 upfront but saves $500/month in cloud bandwidth
5. Data Science & Analytics - Responsibilities: Optimize ML models for edge inference, implement federated learning - Challenges: Model compression (quantization), accuracy vs speed trade-offs - Example: TensorFlow Lite model (5 MB) runs on fog node in 50ms vs cloud (200ms)
Interdependency Examples:
Collaboration
Challenge
Solution Requiring Both Disciplines
Network + Data Science
ML inference latency depends on network RTT
Co-design: optimize model size (Data Science) and deploy at optimal edge location (Network)
Hardware + Economics
Powerful fog hardware costs more
Trade-off analysis: $500 device with 5-year lifespan vs $5,000 device processing 10× more data
HCI + Network
App should adapt to network conditions
Design app that shows “Local Mode” when fog available, “Cloud Mode” during outages (HCI) with automatic failover (Network)
Economics + Data Science
Training ML models in cloud is expensive
Federated learning: train collaboratively across fog nodes (Data Science) reducing cloud costs by 80% (Economics)
Real-World Case Study: Autonomous Vehicle Fog System
Discipline
Contribution
Network Engineering
V2X (Vehicle-to-Everything) communication, 5G connectivity to roadside fog units
Hardware/OS
NVIDIA Jetson edge GPU for real-time inference, containerized software stack
HCI/UX
Dashboard shows “Autopilot Available” only when edge processing confirms <10ms latency
Quantized YOLO model (50ms inference) detects pedestrians, traffic signs, lane markings
Key Lesson: Successful fog computing requires T-shaped professionals (deep in one discipline, broad understanding across all) and cross-functional teams.
The motivations for fog computing fall into three memorable categories:
Category 1: Brick vs Click (Physical Interaction + Rapid Innovation) - Brick: Fog nodes are physically located near users and devices - Enables location-aware services (e.g., retail beacons, smart parking) - Supports mobile users with consistent local services - Click: Rapid deployment and updates without hardware changes - Deploy new services as containers in minutes - A/B test features on subset of fog nodes before global rollout - Example: Retail store deploys fog node for in-store navigation. Updates app weekly with new features, no store visits required.
Category 2: Real-Time Processing (Right Here and Now + Client-Centric) - Right Here and Now: Immediate processing without cloud round trips - <10ms responses for critical applications - Works during internet outages (autonomous operation) - Client-Centric: Personalized local services - Process sensitive data locally (privacy) - Adapt to local context (temperature, traffic, time of day) - Example: Smart home fog gateway controls lights/HVAC in <5ms based on occupancy, maintains schedules during internet outage, keeps camera footage local for privacy.
Category 3: Pooling (Local Resource Pooling + Encrypted Traffic Handling) - Local Resource Pooling: Aggregate nearby device capabilities - Idle phones/laptops contribute processing during off-peak hours - Mesh networks share bandwidth and connectivity - Encrypted Traffic Handling: Process encrypted data without decryption - Homomorphic encryption allows fog nodes to compute on encrypted data - Privacy-preserving analytics (e.g., traffic counting without identifying vehicles) - Example: Smart city fog nodes pool resources from 10,000 devices (set-top boxes, routers, smart meters) to create distributed data center. Process encrypted video analytics without seeing individual faces (privacy-preserving crowd counting).
Cross-Reference: The “Right Here and Now” principle enables Edge AI/ML local inference. The “Pooling” concept relates to Wireless Sensor Networks resource collaboration. See Privacy by Design for encrypted traffic handling techniques.
Show code
viewof kc_fog_6 = {const container =html`<div class="inline-knowledge-check"></div>`;if (container &&typeof InlineKnowledgeCheck !=='undefined') { container.innerHTML=''; container.appendChild(InlineKnowledgeCheck.create({question:"A hospital deploys a patient monitoring system with 200 wearable heart rate monitors. During a network outage, the system must continue alerting nurses to cardiac emergencies. Which fog computing category from the 'BRP' framework is most critical for this use case?",options: [ {text:"Brick vs Click - physical proximity to patients ensures faster response times",correct:false,feedback:"Partially correct. Physical proximity (Brick) does help with latency, but the key requirement here is autonomous operation during network outages. The 'Real-time + Client-centric' category better addresses the offline operation need."}, {text:"Real-time + Client-centric - local processing ensures alerts work even during cloud outages",correct:true,feedback:"Correct! The 'Real-time + Client-centric' category emphasizes 'Right Here and Now' processing that works without cloud connectivity. During a network outage, the fog gateway continues monitoring heart rates locally and triggers alerts through local paging systems - no cloud required for critical functions."}, {text:"Pooling + Privacy - aggregate patient data locally to protect HIPAA compliance",correct:false,feedback:"Incorrect. While privacy (HIPAA compliance) is important, it's not the primary concern when lives are at stake during network outages. The critical requirement is maintaining alerts during outages, which falls under 'Real-time + Client-centric'."}, {text:"All three categories equally - hospital systems require all fog benefits simultaneously",correct:false,feedback:"Incorrect. While all categories are valuable, the specific scenario (network outage + cardiac emergencies) makes 'Real-time + Client-centric' the most critical. Not all requirements carry equal weight in every scenario - understanding which matters most is key to good architecture."} ],difficulty:"hard",topic:"fog-use-cases" })); }return container;}