%% fig-alt: "Decision flowchart for Edge AI vs Cloud AI deployment: Start with latency requirement. If under 100ms needed, Edge AI is required. If over 100ms acceptable, check connectivity. If unreliable or offline operation needed, Edge AI required. If reliable connectivity, check data privacy. If sensitive data that cannot leave device, Edge AI required. If public data, check data volume. If over 1GB per day per device, Edge AI saves bandwidth costs. If under 1GB per day, check model complexity. If simple model under 50MB, Edge AI is efficient. If complex model over 50MB, Cloud AI provides more compute power."
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#2C3E50', 'primaryTextColor': '#fff', 'primaryBorderColor': '#16A085', 'lineColor': '#16A085', 'secondaryColor': '#E67E22', 'tertiaryColor': '#7F8C8D', 'fontSize': '14px'}}}%%
flowchart TD
Start["Application<br/>Requirements"] --> Latency{Latency<br/>Requirement?}
Latency -->|"< 100ms"| Edge1["EDGE AI<br/>Required for<br/>real-time response"]
Latency -->|"> 100ms OK"| Connect{Connectivity<br/>Reliability?}
Connect -->|"Unreliable/<br/>Offline Needed"| Edge2["EDGE AI<br/>Required for<br/>autonomy"]
Connect -->|"Reliable<br/>24/7 Internet"| Privacy{Data<br/>Privacy?}
Privacy -->|"Sensitive<br/>(PII, Medical)"| Edge3["EDGE AI<br/>Required for<br/>compliance"]
Privacy -->|"Public/<br/>Non-sensitive"| Volume{Data<br/>Volume?}
Volume -->|"> 1 GB/day<br/>per device"| Edge4["EDGE AI<br/>Saves bandwidth<br/>costs"]
Volume -->|"< 1 GB/day"| Model{Model<br/>Complexity?}
Model -->|"Simple<br/>(< 50 MB)"| Edge5["EDGE AI<br/>Efficient<br/>deployment"]
Model -->|"Complex<br/>(> 50 MB)"| Cloud1["CLOUD AI<br/>More compute<br/>power"]
style Start fill:#2C3E50,stroke:#16A085,color:#fff
style Edge1 fill:#16A085,stroke:#2C3E50,color:#fff
style Edge2 fill:#16A085,stroke:#2C3E50,color:#fff
style Edge3 fill:#16A085,stroke:#2C3E50,color:#fff
style Edge4 fill:#16A085,stroke:#2C3E50,color:#fff
style Edge5 fill:#16A085,stroke:#2C3E50,color:#fff
style Cloud1 fill:#E67E22,stroke:#2C3E50,color:#fff
316 Edge AI Fundamentals: Why and When
316.1 Learning Objectives
By the end of this chapter, you will be able to:
- Explain Edge AI Benefits: Articulate why running machine learning at the edge reduces latency, bandwidth costs, and privacy risks
- Calculate Business Impact: Quantify bandwidth savings, latency improvements, and cost reductions from edge AI deployment
- Apply Decision Framework: Determine when edge AI is mandatory versus optional based on application requirements
- Understand Privacy Benefits: Design privacy-preserving architectures using edge-first AI processing
ImportantThe Challenge: Running ML on Microcontrollers
The Problem: Machine learning models don’t fit on IoT devices:
| Resource | Cloud Server | Microcontroller | Gap |
|---|---|---|---|
| Model Size | ResNet-50: 100 MB | 256 KB Flash | 400x |
| Compute | Billions of ops/sec (GHz CPU, GPU) | Millions of ops/sec (MHz MCU) | 1000x |
| Memory | GB of RAM for activation buffers | KB of RAM | 1,000,000x |
| Power | 100-300W (GPU server) | 1-50 mW (sensors) | 10,000x |
Why It’s Hard:
- Can’t just shrink models - Naive size reduction destroys accuracy. A 10x smaller model might be 50% less accurate.
- Can’t always use cloud - Latency (100-500ms), privacy (data leaves device), connectivity (offline scenarios), and cost ($0.09/GB bandwidth) make cloud unsuitable for many IoT applications.
- Different hardware has different constraints - A $5 Arduino has different capabilities than a $99 Jetson Nano. One-size-fits-all doesn’t work.
- Training != Inference - Training requires massive datasets and GPUs; inference must run on milliwatts. Different optimization strategies for each.
What We Need:
- Model compression without losing accuracy (quantization, pruning, distillation)
- Efficient inference on low-power hardware (TensorFlow Lite Micro, specialized runtimes)
- Conversion tools to transform cloud models to embedded targets (Edge Impulse, TFLite Converter)
- Hardware acceleration where possible (NPUs, TPUs, FPGAs for critical workloads)
The Solution: This chapter series covers TinyML techniques-quantization (4x size reduction), pruning (90% weight removal), knowledge distillation (transfer learning from large to small models)-and specialized hardware (Coral Edge TPU, Jetson, microcontrollers) that enable running sophisticated AI on devices with less compute power than a 1990s calculator.
316.2 Prerequisites
Before diving into this chapter, you should be familiar with:
- Edge and Fog Computing: Understanding where edge AI fits in the edge-fog-cloud hierarchy and why local processing matters for latency-sensitive applications
- Data Analytics and ML Basics: Familiarity with machine learning fundamentals, model training, inference concepts, and basic neural network architectures
- Hardware Characteristics: Knowledge of IoT device resource constraints (memory, CPU, power) helps contextualize why edge AI requires specialized optimization techniques
TipFor Beginners: What is Edge AI?
Think of edge AI like having a smart security guard at your door instead of calling headquarters for every decision.
Traditional Cloud AI:
Camera sees person ->
Upload photo to cloud (500 KB) ->
Wait 200ms for network round-trip ->
Cloud runs facial recognition ->
Send result back ->
TOTAL: 300-500ms + 1 MB bandwidthEdge AI:
Camera sees person ->
Run recognition ON THE CAMERA ->
Decision in 50ms, zero bandwidth ->
Only send alert if neededReal-World Examples You Already Use:
Smartphone Face Unlock - Your phone processes your face ON the device, doesn’t send your face photo to Apple/Google servers. That’s edge AI protecting your privacy while enabling instant unlock.
Smart Speaker Wake Word - “Hey Alexa” or “OK Google” runs continuously on a tiny chip in the speaker using 1 milliwatt of power. Only after hearing the wake word does it send your actual query to the cloud.
Car Collision Avoidance - Your car’s AI detects pedestrians and obstacles in real-time (under 10ms) without waiting for a cloud connection. At highway speeds, every millisecond counts.
Smart Factory Quality Control - Cameras inspect manufactured parts for defects at 100 items per minute. Sending 100 high-res images to cloud would cost thousands in bandwidth; edge AI processes locally for pennies.
The Three Critical Advantages:
| Problem | Cloud AI | Edge AI |
|---|---|---|
| Latency | 100-500ms | 10-50ms |
| Bandwidth | GB/day per device | KB/day (alerts only) |
| Privacy | Data leaves device | Data stays local |
Key Insight: Edge AI is essential when you need instant decisions, have limited bandwidth, or must protect sensitive data. This chapter teaches you how to shrink powerful AI models to run on tiny devices.
NoteKey Takeaway
In one sentence: Edge AI brings machine learning to IoT devices through model compression techniques (quantization, pruning, distillation) that shrink models 4-100x while preserving accuracy, enabling real-time inference at the data source.
Remember this: If your IoT application needs sub-100ms response times, processes private data, or generates more than 1GB/day per device, edge AI is not optional - cloud latency and bandwidth costs make it mandatory.
TipMinimum Viable Understanding: When Edge AI is Mandatory
Core Concept: Edge AI is required - not optional - when any of four conditions exist: sub-100ms latency, intermittent connectivity, data privacy constraints, or bandwidth costs exceeding hardware costs.
Why It Matters: Many IoT projects default to cloud AI and fail in production. A smart camera generating 100 Mbps of video cannot economically stream to cloud ($500K/month for 1000 cameras). Edge AI reduces this to alert-only transmission ($15K/month) - a 97% cost reduction.
Key Takeaway: Apply the “Four Mandates” test: (1) Need response under 100ms? Edge required. (2) Must work offline? Edge required. (3) Processing private data (faces, health, location)? Edge required. (4) Generating over 1GB/day per device? Edge saves money. If any answer is yes, design for edge AI from day one - retrofitting is 3-5x more expensive.
316.3 Introduction: The Edge AI Revolution


Your security camera processes 30 frames per second. Uploading all footage to the cloud for motion detection requires 100 Mbps of sustained bandwidth and costs $500/month. Cloud-based AI introduces 200-500ms latency-unacceptable for real-time safety alerts.
Running machine learning locally on the camera changes everything: instant threat detection in under 50ms, zero bandwidth costs (only send alerts), and complete privacy (video never leaves the device). This is Edge AI-bringing artificial intelligence to where data is created, not where compute is abundant.
The challenge? Your camera has 1/1000th the computing power of a cloud server and must run on 5 watts of power. This chapter explores why edge AI matters and when to use it.
316.4 Why Edge AI? The Business Case
316.4.1 The Bandwidth Problem
Calculation for a Smart City Camera Network:
Single 1080p camera:
- Resolution: 1920 x 1080 pixels x 3 bytes (RGB) = 6.2 MB per frame
- Frame rate: 30 fps
- Data rate: 6.2 MB x 30 fps = 186 MB/s = 1.49 Gbps (uncompressed)
- With H.264 compression: ~50 Mbps sustained
- 24/7 operation: 50 Mbps x 3,600 seconds x 24 hours = 4.32 TB/day
1,000 cameras in a city:
- Total bandwidth: 50 Gbps continuous
- Monthly data transfer: 1,000 cameras x 4.32 TB/day x 30 days = 129 PB/month
- AWS data transfer cost: $0.09/GB for first 10 TB, less for volume
- Conservative estimate: $100,000-500,000/month in bandwidth costs aloneEdge AI Solution: - Process video locally on camera - Only transmit alerts (when motion/threat detected): ~10 KB per event - 10 alerts per camera per day: 1,000 cameras x 10 alerts x 10 KB = 100 MB/day - Monthly cost: ~$0.01 (essentially free) - Savings: 99.99% bandwidth reduction

Cloud AI vs Edge AI Cost Comparison: Traditional cloud AI requires uploading all video frames (50 Gbps for 1000 cameras, $700K/month), while Edge AI processes locally and only sends alerts (100 MB/month, $15K/month)-a 98% cost reduction. Latency improves from 200-500ms to 50ms for critical real-time decisions.
NoteAlternative View: Edge AI Decision Framework
This variant shows when to choose edge AI versus cloud AI based on application requirements, helping architects make deployment decisions.
Summary: Edge AI is the default choice when latency, privacy, connectivity, or bandwidth are constraints. Cloud AI is only preferred for complex models with reliable connectivity and non-sensitive data.
NoteAcademic Resource: Stanford IoT Course - Edge AI for Object Detection
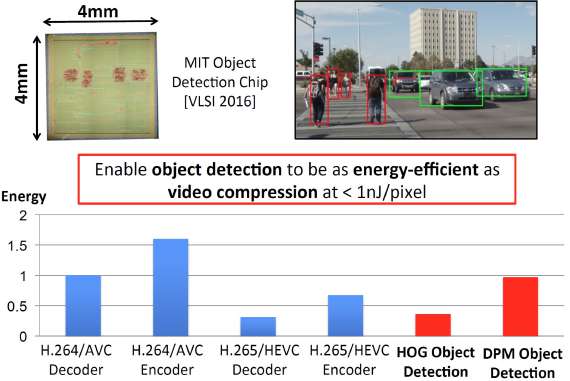
Source: Stanford University IoT Course - Demonstrating how specialized edge AI chips achieve energy-efficient object detection comparable to video compression, enabling real-time computer vision on battery-powered devices
316.4.2 The Latency Problem
Critical Use Cases Where Milliseconds Matter:
| Application | Cloud Latency | Edge Latency | Why It Matters |
|---|---|---|---|
| Autonomous Vehicles | 100-500ms | <10ms | At 60 mph (27 m/s), 100ms delay = 2.7 meters traveled blind. Collision avoidance requires <10ms brake response. |
| Industrial Safety | 150-300ms | 20-50ms | Worker approaching danger zone needs instant warning. 300ms might be difference between minor incident and fatality. |
| Medical Devices | 200-400ms | 10-30ms | Glucose monitor detecting dangerous insulin level must alert in <50ms to prevent diabetic shock. |
| Smart Grid Protection | 100-250ms | 5-15ms | Power surge detection requires sub-cycle (<16.7ms at 60 Hz) response to prevent equipment damage. |
Latency Breakdown for Cloud AI:
Network transmission to cloud: 50-150ms (depends on distance, congestion)
Queueing at cloud server: 10-50ms (depends on load)
Model inference: 20-100ms (depends on model size)
Network transmission back: 50-150ms
TOTAL: 130-450ms (best to worst case)
Edge AI:
Data already on device: 0ms
Model inference: 10-50ms (optimized edge model)
TOTAL: 10-50ms (5-10x faster)316.4.3 The Privacy Problem
GDPR and Data Privacy Requirements:
Edge AI enables Privacy by Design-data never leaves the device, ensuring compliance with GDPR, HIPAA, and other regulations without complex data governance frameworks.
Real-World Privacy Scenarios:
- Smart Home Security Camera
- Cloud AI: Your video streams to company servers (potential breach, subpoenas, employee access)
- Edge AI: Facial recognition runs on camera, only sends “Person X detected” alert (no video stored externally)
- Healthcare Wearables
- Cloud AI: Heart rate, glucose, location data transmitted continuously (HIPAA concerns)
- Edge AI: Anomaly detection on device, only alerts doctor when metrics critical
- Workplace Monitoring
- Cloud AI: Employee video/audio analyzed externally (consent issues, surveillance concerns)
- Edge AI: On-premise processing respects privacy, only aggregate productivity metrics leave building

Edge AI Privacy Architecture: Sensitive sensor data (images, audio, location) stays on the device for local ML inference. Only privacy-preserving insights (aggregated statistics, anonymized alerts) are transmitted to cloud, ensuring GDPR/HIPAA compliance by design and eliminating data breach risk.
WarningCommon Misconception: “Edge AI is Always Faster Than Cloud”
The Misconception: Processing locally is always faster than sending to the cloud.
Why It’s Wrong: - Model loading takes time (especially first inference) - MCU inference can be slow (no GPU/TPU acceleration) - Complex models may be impossible to run locally - Cloud can batch and parallelize across many requests
Real-World Example: - Image classification on ESP32: - Model load: 500ms (first time) - Inference: 200ms per image - Total: 700ms first, 200ms subsequent - Cloud (AWS Lambda): - Network round-trip: 100ms - Inference: 50ms (GPU) - Total: 150ms (faster for single images!)
The Correct Understanding: | Scenario | Edge Wins | Cloud Wins | |———-|———–|————| | Continuous stream | checkmark (no network per frame) | | | Single inference | | checkmark (faster hardware) | | Privacy critical | checkmark (data stays local) | | | Complex model | | checkmark (can run larger models) | | No connectivity | checkmark (works offline) | | | First inference | | checkmark (no model load) |
Edge AI wins on privacy, bandwidth, and sustained throughput. Cloud wins on one-off complex tasks.
316.5 Knowledge Check
316.6 Summary
Edge AI provides critical benefits for IoT applications:
Key Benefits: - Latency Reduction: 10-50ms inference vs 100-500ms cloud round-trip (5-10x faster) - Bandwidth Savings: 99%+ reduction by processing locally and sending only alerts - Privacy by Design: Sensitive data never leaves device (GDPR/HIPAA compliant) - Resilience: Continues operating during network outages - Cost Efficiency: Eliminates cloud bandwidth and compute costs at scale
The Four Mandates - Edge AI is required when: 1. Sub-100ms latency needed (safety-critical, real-time control) 2. Offline operation required (intermittent connectivity) 3. Privacy constraints (medical, biometric, personal data) 4. High data volume (>1GB/day per device)
316.7 What’s Next
Now that you understand why and when to use edge AI, continue to:
- TinyML: Machine Learning on Microcontrollers - Learn how to run ML on ultra-low-power devices with as little as 1 KB RAM
- Model Optimization Techniques - Master quantization, pruning, and knowledge distillation to compress models 10-100x
- Hardware Accelerators for Edge AI - Choose the right NPU, TPU, GPU, or FPGA for your application